
Recently I had the opportunity to attend Cloud Field Day 4 in Silicon Valley. While in attendance, one of the briefings I attended was provided by Cohesity. For those who are not already familiar with Cohesity, It was founded in 2013 by Mohit Aron. Aron cofounded Nutanix and was previously lead on Google filesystem. So it’s safe to say that he created Cohesity with a solid foundation in storage. The platform was created as a scale out secondary storage platform. But as I discovered during my time there, the use cases for Cohesity’s platform have grown very broadly beyond a secondary place to store data.
Cohesity spent very little time getting the delegates up to speed on their platform and the SpanFS Distributed fileystem that powers it. That information has been covered in past Field Day events and can be found in archived videos. We spent the majority if our time with Cohesity covering higher level features and functionality which I will review in this blog post.
Cloud Adoption Trends
The first “session” of the briefing was delivered by Sai Mukundan and past Field Day delegate Jon Hildebrand.
Sai covered some of the trends that Cohesity sees in customer adopting cloud and the Cohesity Data Platform specific use case. The first use case being long-term retention and VM-migration.
Because Cohesity supports AWS, Azure, GCS, and any S3 compatibly object storage, a customer can choose the cloud storage provider that suits them best as a target for long-term storage of their data. Indexes of customer data can enable search across local and cloud instances of data stored by Cohesity. This is especially valuable in helping customers to avoid unnecessary egress charges when a file already exists on-premises.
My favorite part of most briefings is the demos of course, and Cohesity did not disappoint. During his time in the limelight, Jon showed off how he could create a policy that would archive data to multiple public clouds at once. In this case, he created a single policy that would archive data to AWS, Azure, and GCP all at the same time. I actually managed to get a question in during this demo to and in case you are curious, not only can you set a bandwidth limit for each cloud target but also a global limit to ensure that the aggregate of your cloud archive jobs will not consume an unwanted amount of bandwidth. Jon and Sai also showed that once the data exists in multiple locations all will be shown when a restore is initiated.
Migration of VMs Is handled in Cohesity by a feature named “CloudSpin”
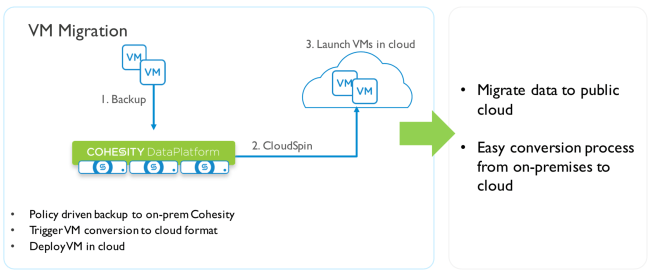
This feature was also showcased in demo form. I won’t describe the demo in detail because you can just watch it at your leisure. I will however mention one thing that struck me during Cohesity’s briefing. The UI is not only slick and responsive, but also well thought out. While watching demos I was impressed by how intuitive everything seemed and how easy I felt navigating the platform would be for someone who was unfamiliar with the interface.
Application Test/Dev
Within the context of VM Migration that was previously mentioned, another potential use case of the Cohesity platform is application mobility for the purposes of testing and development. Again, this functionality was demonstrated rather than just explained.
Again, I won’t spend a lot of time rehashing what took place during the demo. But as the demonstration of the power available to developers unfolded, the panel of mostly infrastructure professionals started discussing the implications of these capabilities brought up concerns about access and cost control. The Cohesity team did a very good job of addressing roles with built-in RBAC capabilities, but it is clear that there is no built-in cost control capability at this point in time. It was pointed out that the extensibility of the platform through use of APIs means that customers could implement cost control using a third party management plane of their choice. This is an indirect answer the question though, and I would like to see Cohesity implement these features natively. A customer can make the decision to implement them in the Cohesity platform, leverage a third party management plane, or simply let the developer run wild (bad idea.)
Cloud Native Backup
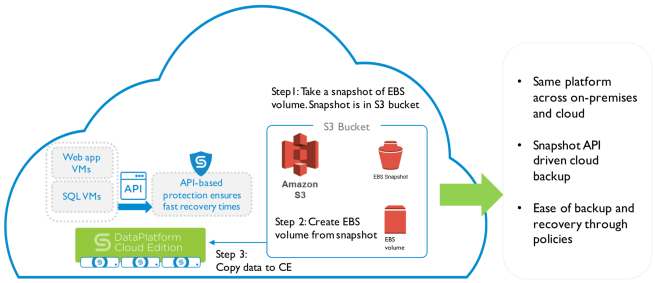
Within the Cohesity model, cloud-native backups are a three step process. The image below depicts the scenario specific to AWS, but the process for Azure or GCP workloads is largely the same. First, a snapshot of an EBS volume is taken and placed in an S3 bucket. Second, the snapshot is transformed into an EBS volume. To complete the process, the volume is copied to Cohesity Cloud Edition.
Multi-Cloud Mobility
A common first use-case for many customers when they initially put data into the cloud is for long term retention. With this in mind, Cohesity seeks to enable customers to store an move data to the cloud provider of their choice. The three big clouds (AWS, Azure, and GCP) are all supported, but a customer could choose to leverage an entirely different service provider as long as they offer NFS or S3 compatible storage.
I expected Cohesity to show of some kind of data movement feature during a demo of this use case, but I was wrong. What I got instead was data consistency with Cohesity, even when data that had been archived to one cloud vendor was migrated to another by a third party tool. This ensures that the cluster will maintain access to the data and be able to continue performing such tasks as incremental backup. This is accomplished by changing the metadata within a Cohesity cluster. There are multiple ways to execute this task, be it GUI, API, or in the case of the demo, a CLI tool called icebox_tool.

Summary
While Cohesity may have started life as a “Hyper-Converged Secondary Storage” platform, the use cases have increased greatly as the platform has matured. While this makes for a very powerful platform that can fit a multitude of customer types, it has led to confusing messaging.

Is Cohesity a data archival platform, a backup platform, or a data mobility platform? The answer is “all of the above” which is fine, but doesn’t really help deliver a clear message that can be brought to market and keep the product at the front of mind for customers who are seeking a product to address their needs.
I’m not a marketing genius so I have no idea what this message would look like. However, Cohesity has been bringing in a lot of top talent lately and I think they should have no problem clearing confusion that exists around their platform. Because it is clearly a powerful and capable platform and once customers know off all the use cases and how the product is relevant to them, it is sure to gain popularity.

One thought on “Cohesity: Much More than Hyperconverged Secondary Storage”